- 功能介绍
- Compactness(CP), CP越低意味着类内聚类距离越近
- Seperation(SP), SP越高意味类间聚类距离越远
- Davies-Bouldin Index(DB), DB越小意味着类内距离越小 同时类间距离越大
- Calinski-Harabasz Index(VRC), VRC越大意味着聚类质量越好
- 参数说明
- 脚本示例
- 脚本代码
- 脚本运行结果
功能介绍
聚类评估是对聚类算法的预测结果进行效果评估,支持下列评估指标。
Compactness(CP), CP越低意味着类内聚类距离越近
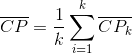
Seperation(SP), SP越高意味类间聚类距离越远
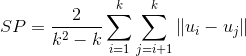
Davies-Bouldin Index(DB), DB越小意味着类内距离越小 同时类间距离越大
Calinski-Harabasz Index(VRC), VRC越大意味着聚类质量越好
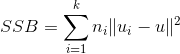
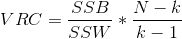
参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 默认值 | |
|---|---|---|---|---|---|---|
| labelCol | 标签列名 | 输入表中的标签列名 | String | null | ||
| vectorCol | 向量列名 | 输入表中的向量列名 | String | null | ||
| predictionCol | 预测结果列名 | 预测结果列名 | String | ✓ | ||
| distanceType | 距离度量方式 | 聚类使用的距离类型,支持EUCLIDEAN(欧式距离)和 COSINE(余弦距离) | String | “EUCLIDEAN” |
脚本示例
脚本代码
import numpy as npimport pandas as pddata = np.array([[0, "0 0 0"],[0, "0.1,0.1,0.1"],[0, "0.2,0.2,0.2"],[1, "9 9 9"],[1, "9.1 9.1 9.1"],[1, "9.2 9.2 9.2"]])df = pd.DataFrame({"id": data[:, 0], "vec": data[:, 1]})inOp = BatchOperator.fromDataframe(df, schemaStr='id int, vec string')metrics = EvalClusterBatchOp().setVectorCol("vec").setPredictionCol("id").linkFrom(inOp).collectMetrics()print("Total Samples Number:", metrics.getCount())print("Cluster Number:", metrics.getK())print("Cluster Array:", metrics.getClusterArray())print("Cluster Count Array:", metrics.getCountArray())print("CP:", metrics.getCompactness())print("DB:", metrics.getDaviesBouldin())print("SP:", metrics.getSeperation())print("SSB:", metrics.getSsb())print("SSW:", metrics.getSsw())print("CH:", metrics.getCalinskiHarabaz())
脚本运行结果
Total Samples Number: 6Cluster Number: 2Cluster Array: ['0', '1']Cluster Count Array: [3.0, 3.0]CP: 0.11547005383792497DB: 0.014814814814814791SP: 15.588457268119896SSB: 364.5SSW: 0.1199999999999996CH: 12150.000000000042
